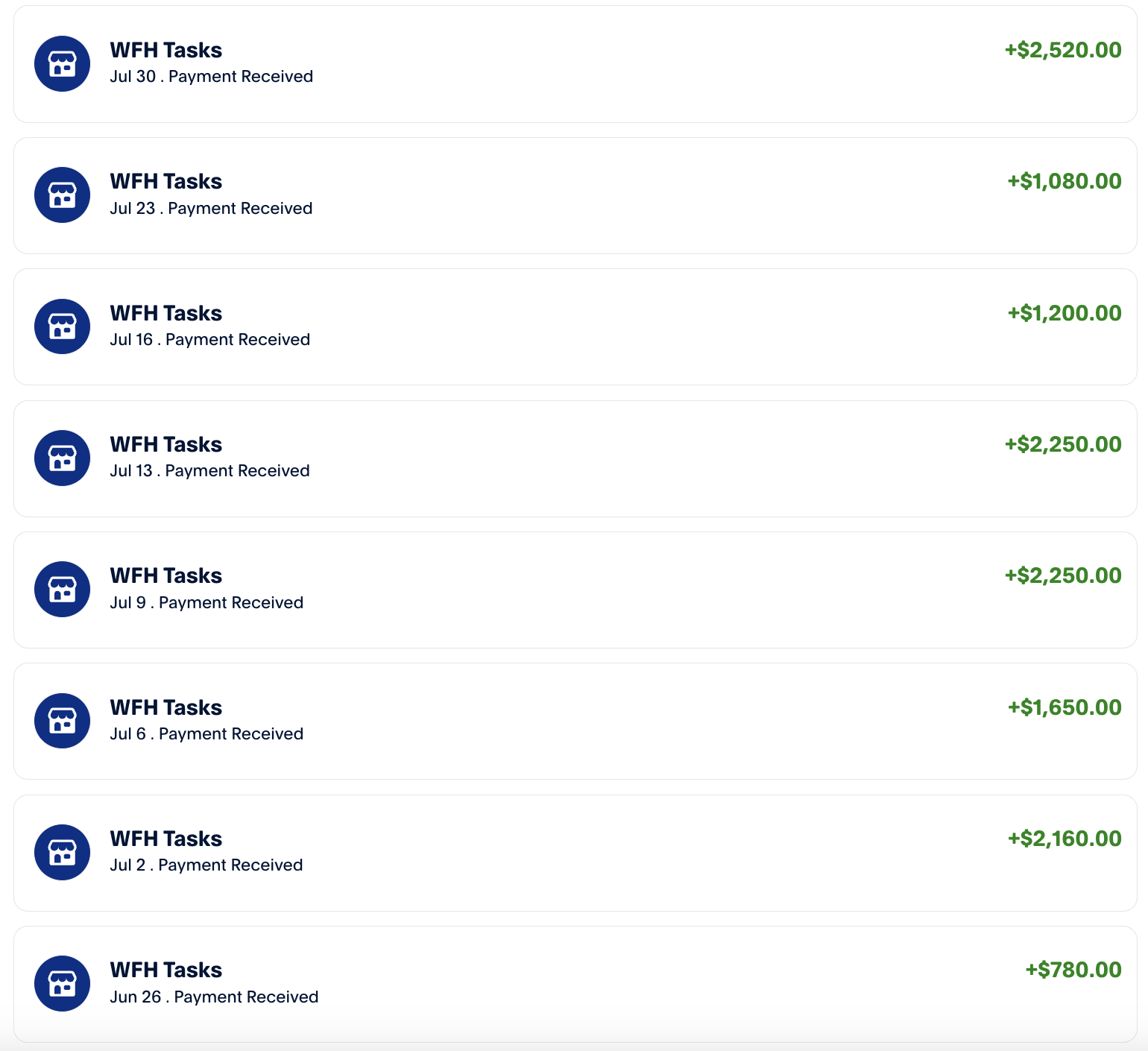
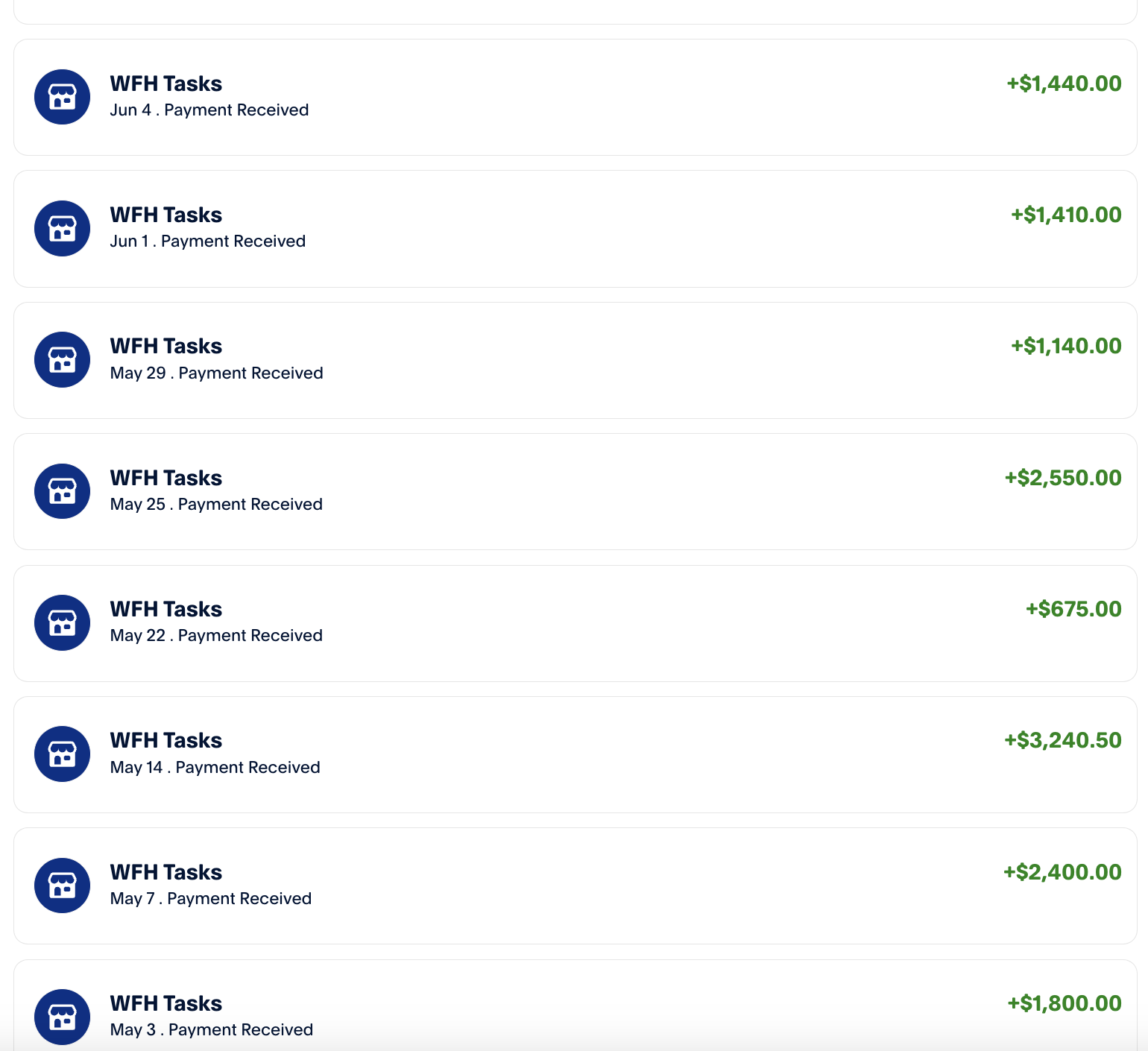
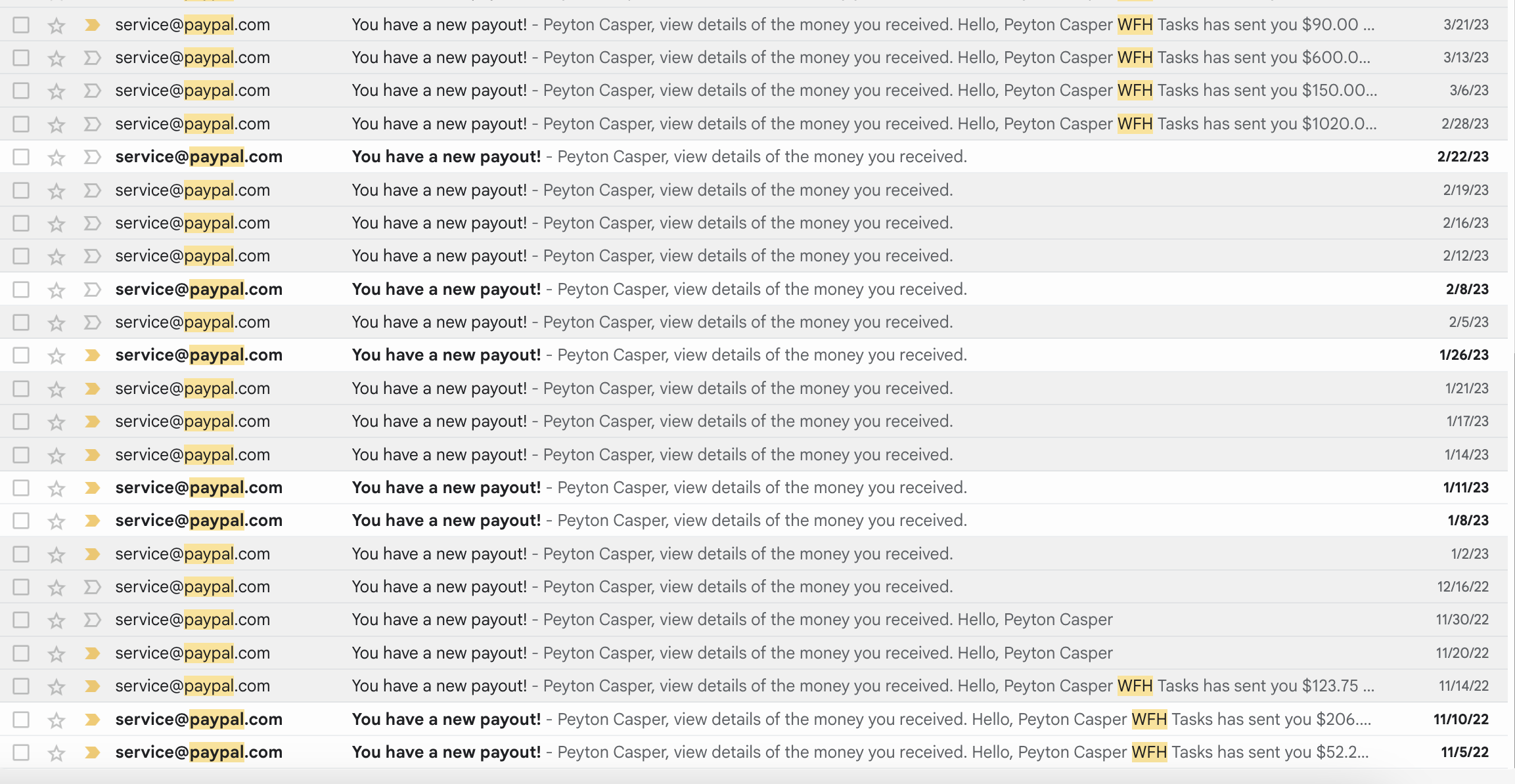
Given the way startups are currently accounting for revenue, I technically hit $120k in ARR back in 2023. Companies like Scale AI, Mercor and DataAnnotation Tech are essentially labor farms, but there is an interesting arbitrage opportunity if you are at the bleeding edge of what models are capable of. Turns out you can automate pretty much all of the work that they hand out with the proper framework.
The Automated Data Annotation Framework
If you break a particular task down along these lines, then you can automate significant aspects of this annotation work with Computer Use, VLMs and Reasoning models.
Let's start from the top with my most recent example. A LARGE_AI_LAB wanted to teach their models to critique and generate better UIs from a given prompt. So to do this we worked backwards by taking a website, injecting a mistake and then capturing screenshots along with a description of the mistake.
1Idea Creation
We like to think of idea generation as something unique to humans, but it's actually a search space at its core. All the ideas in the world exist as things we haven't tracked and so if you simply build a searchable index of all the ideas you ever generate then you can ensure that you generate unique ideas by checking your index of generated ideas and retrying with randomness until a new one is found.
I know what you're thinking. Peyton, you used reasoning models for this use case. Well you're wrong. Despite many people in SF declaring RAG is dead, standard GPT-4o with the right temperature setting and a vector index is all you need.
2Problem Design
Alright, let's go back to our goal. We need to generate bugs on a website and capture the results. First we will start with a large collection of public URLs and then we'll have our IDEA_GENERATION step come up with 10 potential visual bugs to inject into a website, by giving it the HTML and the ability to query past visual bugs that worked well.
3Solution Design
The next step is to inject our bug into the HTML, render it in a browser and then capture a screenshot.
You're probably thinking, we still need to document the bug and generate a description. Well, let's grab a reasoning model for fun.
<PROMPT>
I have included two screenshots. The first one is the website without a visual
artifact and the second one is the website with a visual artifact.
I need you to evaluate the severity of this bug along the following lines and
generate a short 2 sentence description for each category.
1. Accessibility
2. Color/Theme
3. Typography
4. Iconography
Here is the original tag:
<div></div>
Here is the modified tag:
<div style="injected"></div>
In addition, I need you to generate a description of the modification you made
to the HTML.
Lastly, you must format your response as valid JSON with the following schema.
{
"accessibility": "string",
"theme": "string",
"typography": "string",
"iconography": "string",
"desc": "string"
}
</PROMPT>Great, so now we have before/after screenshots, descriptions of our bug along with categories and a technical description of the change we made. And to top it all off, it comes back in JSON format which makes it easy to plug into the next step.
4Data Entry
The final step for this particular problem is to enter all this data into an annotation platform built by the given annotation client and simple Browser Agents can take our JSON from the previous step and enter it into the proper fields.
5Validation
This is sort of baked into the previous steps for this particular task, but this typically includes things like making sure something compiles, matches expectations or just generally works as expected.
Moving On
This forms the basis of synthetic data technically, but by breaking it down and injecting the minimal amount of human intelligence into the process we get results that pass the tests. There are some challenges such as ensuring text doesn't sound like an LLM but I was able to take this general framework and scale agents that would run for 20 hours/day completing tasks while I did other things.
The limiting factor, ironically, was actually human identities, because I only have one SSN.
Why Now
This experience forms the basis for what I am doing at CoffeeBlack AI. All of this work was done under the covers, but I want to work directly with companies that do this type of work. Colloquially they are all classified as Business Process Outsourcing (BPO), but they perform repetitive tasks in HR, Logistics, Annotation, IT Services, Customer Service, etc.
BPOs will transform into the traditional software partner network and will be experts at digitizing workflows while we sell the platforms/tools that enable this new wave of productivity. Mechanical labor will continuously be commoditized over the next few years with the only remaining bastions of work being creativity and turning that into mechanical automation as fast as possible.
My Thesis
At the core of every business are thousands of processes that with intelligent tooling will amplify the impact of a single employee.
Proof
I am also happy to jump on a call and screenshare my PayPal in realtime.